GoogleのAlphaGoが、囲碁の世界ランキング4位にランキングされました。世界ランク4位だったLee Sedolに4勝1敗したのですから、当然ですね。
AlphaGoに使われているDQN(Deep Q-Network)というアルゴリズムが最初に攻略したのはスペースインベーダー。「スコアを最大にせよ」という単純極まりない指示に対して、最初はまったく歯がたたない状態から何度も何度も対戦を繰り返すことで、最終的には一発も無駄な弾を使わずに、エレガントに最高得点を叩き出すまでに学習しました。
次にチャレンジしたのが、ブロック崩し。こちらも4時間程度で人間には思いつかないような新しい技を繰り出すようになりました。
こうしてDQNは、まずAtari2600用の49種のTVゲームを攻略しました。
DQNの学習過程はどれも同じような経過を辿ります。最初まったく試合にならないほど弱く、失敗ばかりを繰り返します。しかしこの過程で、玉の動きや敵の動き方、玉の打ち返しかたなどを、数多くの経験から少しづつ学習していきます。失敗を繰り返しながらゲームでの動き方を学びます。下手ながらもだんだんゲームが続くようになると、今度はいろいろな状況を経験し、様々な対応を試しながら、徐々にゲームに勝つリズムを会得していきます。そうしてあるところから人間の技を越えていくのです。
この学習過程は、人間の上達の仕方とそっくりです。前回ご紹介した

の上達曲線がこれ↓です。
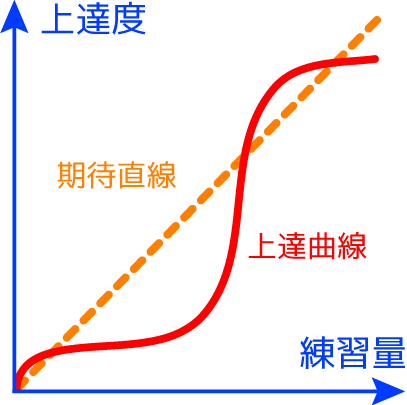
ヒトも人工知能も、学習において、なかなか上達しない時期が極めて重要だということを示唆しています。そこでの地道な経験蓄積と練習量が、のちの実力急上昇につながります。
そしてかなり上達しきったところから、ヒトにはなかなかマネのできない人工知能の恐ろしい一面を発揮しはじめます。上達度があがればあがるほど、練習量を増やしてもなかなか上達できなくなってきます。テニスの錦織圭が世界ランク8位以内に入ってから、世界ランク4位以内にすんなりとは入れないのと同じです。そこから先は、超高度な練習の質と量が求められる未知の世界です。人並みならぬ精神力と技術力が必要とされます。人工知能はこの領域で、まったく疲れを知らずに黙々と莫大な練習量をこなすことができます。
囲碁のチャンピオンは、世界一の囲碁センスを持っているとはいえ、人工知能の練習量には負けます。ヒトには過去のすべての棋譜を試すことは不可能ですが、人工知能には可能です。ある意味、世界一のチャンピオンは、自分以上の相手がいないので、今以上質の高い練習はできないということになります。DQNは、その壁を大量の練習量で越えようとします。今回の囲碁対戦においても、AlphaGoが過去にないような戦い方で勝利したことが注目を浴びました。
人工知能はこれから、トップレベルのよき対戦相手となっていくでしょう。ゲーム的な要素をもった実社会のあらゆるヒトの行為に対して、いままでヒトにはできなかった回答を出すようになるでしょう。しかしそれによってヒトの能力の限界もまた解放され、より高みへと進化するように思います。
錦織圭が人工知能と俊敏なマシンを組み合わせた仮想対戦相手と対戦することで、ジョコビッチもどきと何度も何度も繰り返し対戦できるとしたら、どうでしょう?ジョコビッチの攻略法がより見つかりやすくなるに違いありません。
人工知能はヒトの進化を加速させることになると私は信じています。



- 投稿タグ
- 技術蓄積




